Harnessing the Power of Multi-Cluster Argo Workflows with KubeStellar

In this post, we will explore a novel approach to distributing Argo Workflows across multiple Kubernetes clusters.
Understanding the Basics: Argo Workflows
Argo Workflows, an open-source, container-native workflow engine, is designed specifically for Kubernetes. It’s a powerful tool that orchestrates multi-step tasks, manages data and resource dependencies, and facilitates batch processing, infrastructure automation and ML workflows. It’s no wonder that Argo Workflows has become an integral part of popular cloud-native AI/ML projects like Kubeflow Pipelines.
The Need for Multi-Cluster Workflows
But why would you want to run these workflows on multiple clusters? The answer lies in the unique needs of your organization. Today, most organizations operate multiple Kubernetes clusters for a variety of reasons, including environment isolation, account management, data sovereignty, and resource heterogeneity.
One intriguing scenario that I’ve been exploring within my organization is the distribution of workloads across multiple Kubernetes clusters. It’s a common issue: some clusters are under-utilized, while others are nearing capacity. The obvious solution might seem to be adding more worker nodes to the cluster, but this approach has practical limitations, especially in multi-region and multi-geography scenarios.
So, what happens when we realize we need a multi-cluster solution? That’s where KubeStellar comes into play.
Introducing KubeStellar: A Game Changer
KubeStellar, a CNCF Sandbox Project, is a game-changer in the realm of Kubernetes. It simplifies the deployment and configuration of applications across multiple Kubernetes clusters, providing users with a seamless experience that feels like using a single cluster. With KubeStellar, users define binding policies and deploy workloads using standard Kubernetes tools, making multi-cluster operations a breeze. KubeStellar offers a versatile platform accommodating a broad spectrum of applications, from edge computing to artificial intelligence and machine learning in hybrid and multi-cloud environments. At the core of KubeStellar are two fundamental concepts:
- Workload Definition Space (WDS): This is a user-friendly interface designed to expose a Kubernetes API server interface, allowing users to submit and manage their workloads. Additionally, it gives users the ability to set the binding policies that govern how these workloads are allocated within the system.
- Inventory and Transport Space (ITS): Through this feature, users can maintain an inventory of managed clusters to orchestrate the distribution of workloads across them, ensuring they are delivered and run where specified in the binding policies.
Before discussing how Argo Workflows operates with KubeStellar, let’s go over a quick overview of Workflows.
A Closer Look at Workflows
Argo Workflows are defined and managed through a Kubernetes custom resource known as a Workflow. This critical resource serves two primary functions:
- Defining the Workflow Execution: Specific workflow steps to be carried out are specified within the Workflow
specstructure, which is composed of a list oftemplatesand anentrypoint. Theentrypointdesignates the initial template or the “main” function to execute first. - Storing the Workflow State: As workflows execute, their live state is maintained within the Workflow object itself, rendering it a dynamic entity that both represents the workflow definition and its real-time status.
A Workflow consists of template definitions, which may include containers, scripts or resources, and template invocations, which are used to invoke other templates and control execution flow. These are mainly of two kinds:
- Steps: defines tasks in a series of sequential steps or parallel groups, supporting conditional execution via when clauses.
- DAG (Directed Acyclic Graph): structures tasks as a graph of dependencies, where tasks can run concurrently based on their dependencies’ completion.
A hallmark feature for integration with KubeStellar is the spec.suspend flag, enabling users to pause workflows before initiation. This capacity allows workflows to be synchronized with another cluster via KubeStellar, facilitating remote execution.
The Architecture: KubeStellar and Argo Workflows
Let’s explore the synergy between KubeStellar and Argo Workflows in enabling multi-cluster workflows.

Figure 1 illustrates the setup for Multi-Cluster Argo Workflows. Key components include:
- Argo Workflows: installed on the Control Cluster and multiple Workflow Execution Clusters (WECs).
- KubeStellar: installed on the Control Cluster (and with agents on the WECs), it synchronizes Workflows
specfrom the Control Cluster to the WECs andstatusfrom the WECs to the Control Cluster. - S3 Artifact Store: provides common storage for all Argo Workflow instances.
KubeStellar BindingPolicies define how workloads correlate with their destined execution clusters:
- Workloads: Identified using
objectSelectors. - Clusters: Assigned through
clusterSelectors.
In the setup described in this post, workflows and clusters are identified by label selectors. Workflow without the specified labels and with the suspend flag not set are executed on the control cluster.. Workflows configured with the spec.suspend=true and matching labels for binding policies are executed on the remote clusters.
The KubeStellar controller watches objects that match the policy labels. When a matched object is created in the control cluster (also the WDS), the controller packages it in a manifest, delivering it to the selected WEC through the ITS layer.
Both the ITS and the KubeStellar controller ensure constant up-sync of the Argo Workflow status from the WEC back to the control cluster. To enable seamless operation, it’s imperative to exclude the spec.suspend flag and certain Argo-specific labels from propagating to the remote Argo Workflow instance. Here, KubeStellar's CustomTransform feature filters user-defined fields within workload objects prior WEC down-sync.
Let’s now setup a dev environment to test drive Argo Workflows and KubeStellar working together.
Demo Setup
Ensure that your environment satisfies the prerequisites for KubeStellar. Given that you’ll be establishing three kind clusters, it’s important to expand your resource limits prior to executing the setup script. For ease of installation and configuration of integrations with various projects, including Argo Workflows, the KubeStellar community offers the galaxy repository. You can clone the repository using the following command:
git clone https://github.com/kubestellar/galaxyand then run the setup script.
cd galaxy/scripts/argo-wf
./install-all.shThe script does the following:
- Spins up three kind clusters.
- Installs KubeStellar on the control cluster.
- Registers the remaining two clusters with the control cluster.
- Sets up a KubeStellar CustomTransform to filter out the
suspendflag and Argo-specific labels. - Deploys Argo Workflows across all clusters.
- Configures the Workflow Execution Clusters to use a shared S3 (MinIO) Artifact Store hosted on the Control Cluster.
Be patient, as the script execution may take several minutes. Upon completion, the script log should display accessible URLs for Argo and MinIO:
you can access the argo console at https://argo.localtest.me:9443
+ echo 'you can access the minio console at http://minio.localtest.me:9080'
you can access the minio console at http://minio.localtest.me:9080Running Your First Multi-Cluster Scenario
You are now ready to run your first Argo Workflows on Multi-Cluster. The samples directory contains few examples of workflows (you may find more examples in the argo project). Let’s start by running a “hello world” workflow:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
namespace: argo
labels:
workflows.argoproj.io/archive-strategy: "false"
kubestellar.io/cluster: cluster1
annotations:
workflows.argoproj.io/description: |
This is a simple hello world example.
spec:
suspend: true
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["hello world"]Note how that the spec.suspend flag is set to true, and the workflow has the label kubestellar.io/cluster: cluster1. This label matches the binding policy defined in the file samples/wf-binding-policy-cluster1.yaml:
apiVersion: control.kubestellar.io/v1alpha1
kind: BindingPolicy
metadata:
name: workflows-cluster1
spec:
wantSingletonReportedState: true
clusterSelectors:
- matchLabels:
name: cluster1
downsync:
- objectSelectors:
- matchLabels:
kubestellar.io/cluster: cluster1To start the workflow, just run the command:
kubectl create -f samples/argo-wf1.yamlWe can run the following commands to verify that the workflow is running and that a pod for hello-world has been started on cluster1:
$ kubectl get workflows -n argo
NAME STATUS AGE MESSAGE
hello-world-f9kqn Running 2s
$ kubectl get pods -n argo --context cluster1
NAME READY STATUS RESTARTS AGE
argo-server-788d77f579-8hxsv 1/1 Running 0 30m
hello-world-f9kqn 0/2 PodInitializing 0 11sOnce the workflow completes, we can check for completed status:
$ kubectl get workflows -n argo
NAME STATUS AGE MESSAGE
hello-world-f9kqn Succeeded 4m23s Let’s try now with a more complex example:
kubectl create -f samples/dag-nested.yaml Let’s use the Argo Workflows UI to check the progress of this workflow. Open the url https://argo.localtest.me:9443/ with your browser, and you should be able to get a lot of details about the running workflow:
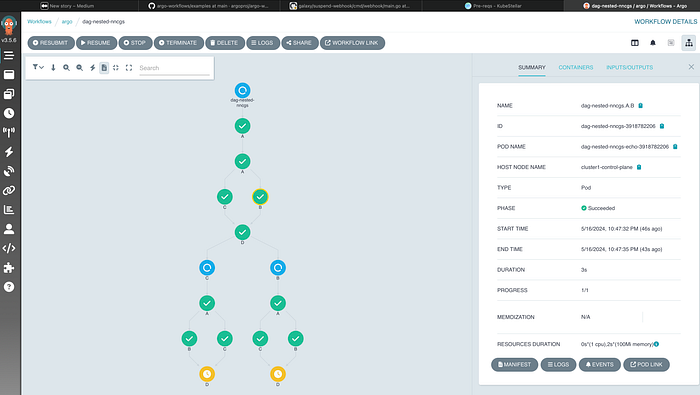
Note how the HOST NODE NAME shows cluster1-control-plane since the task is running on a node in cluster1. Clicking on the logs button, should even provide the log for the selected task:
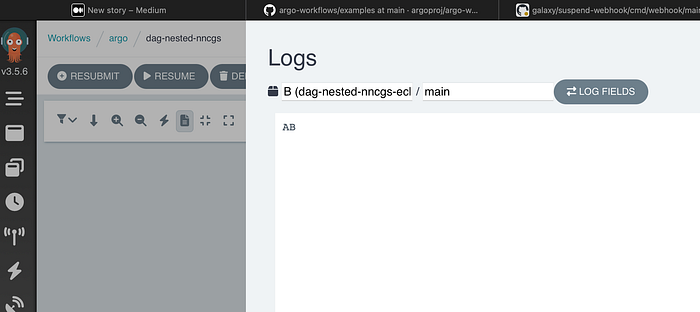
Conclusion
By integrating KubeStellar with Argo Workflows, multi-cluster orchestration becomes both streamlined and transparent, viewable from a single interface. Here we’ve only touched upon the basic features; KubeStellar boasts a wealth of advanced functionalities for managing and configuring multi-cluster workloads.
As of the publication of this post, I am also engaged in enhancing KubeStellar with support for KubeFlow Pipelines, leveraging the Argo Workflow integration showcased earlier. For more details and examples, please consider exploring kubestellar.io. If our work resonates with you, we would appreciate your support — give our GitHub repository a star at https://github.com/kubestellar/kubestellar.
Stay connected for forthcoming articles on this evolving work.